

.

Orkiestracja LLM
Czym jest?
Warstwa zarządzająca i koordynująca działanie dużych modeli językowych w aplikacjach AI – automatyzuje inżynierię promptów, wywołania API, pobieranie danych, zarządzanie pamięcią i monitorowanie.
Po co?
LLM same w sobie mają ograniczenia: tracą kontekst w długich rozmowach, nie uczą się w czasie rzeczywistym, a integracja wielu modeli i agentów szybko staje się chaotyczna. Orkiestracja to rozwiązuje.
Jak działa? Warstwa orkiestracji spina razem LLM (od różnych dostawców), szablony promptów, bazy wektorowe i agentów AI. W podejściu wieloagentowym każdy agent obsługuje inne podzadanie – razem działają sprawniej i skalowalniej.
Kluczowe funkcje: Zarządzanie promptami, integracja API, pobieranie i preprocessing danych, pamięć kontekstu między sesjami, monitorowanie wydajności, load balancing, bezpieczeństwo i kontrola wersji.
Główne korzyści: Skalowalność, niższe koszty, niezawodność, szybszy development, niższy próg wejścia dla zespołów.
Popularne frameworki: LangChain, IBM watsonx Orchestrate, AutoGen (Microsoft), LlamaIndex, Haystack.
„Zgodnie z zasadami transparentności i nadzoru, generatywny model LLM nie powinien pełnić jednocześnie roli wykonawcy i audytora własnych wyników.
Aby uniknąć konfliktu interesów i błędów poznawczych modelu, niezbędna jest niezależna walidacja zewnętrzna.

Tylko obiektywna weryfikacja, zgodna z wytycznymi ESE i ramami OS-Trinity, gwarantuje bezstronność oraz rzetelność oceny bezpieczeństwa systemu.”

Demo interaktywne — symulacja działania systemu
To demo prezentuje symulowany przepływ analizy Trinity. Dane wejściowe, przebieg procesu i wygenerowany wynik są predefiniowane i służą wyłącznie jako ilustracja architektury systemu — pokazują jak wygląda rzeczywista praca Trinity od momentu wprowadzenia zapytania do wydania werdyktu decyzyjnego.
Demo odwzorowuje rzeczywisty przepływ pracy systemu na predefiniowanym scenariuszu: konflikcie między analizą inwestycyjną a danymi klinicznymi. Wyniki, metryki i werdykt są symulowane — celowo, aby pokazać zachowanie systemu w warunkach krytycznych.
To nie jest chatbot do rozmów. To jest warstwa walidacyjna.
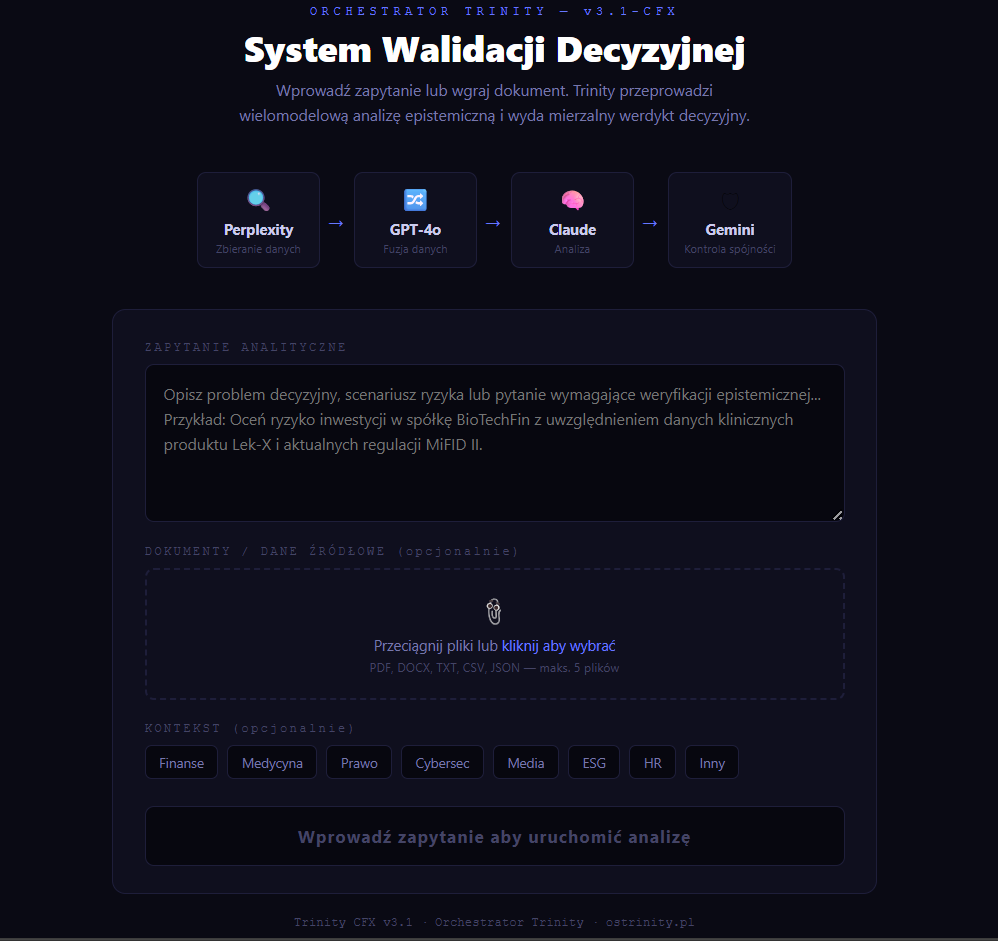
Ten interfejs to wyłącznie symulacja (prototyp Lo-fi), która obrazuje proces walidacji, ale nie wykonuje realnych obliczeń.
Kluczowe funkcje symulacji:
- Ekran wejściowy: Pokazuje, jak użytkownik wprowadza zapytanie, załącza pliki i wybiera kontekst branżowy (np. Medycyna, Finanse).
- Proces „Loading”: Wizualizuje etapy pracy systemu — od zbierania danych przez cztery modele (Perplexity, Grok, Claude, Gemini) po ich fuzję i analizę spójności.
- Panel Wyników (Trinity Full): Prezentuje docelowy sposób raportowania, w tym:
- Wskaźnik ORS: Mierzalny poziom rygoru i pewności decyzji.
- Metryki (TF, CMF): Wizualizację tarcia logicznego i siły wykrytych konfliktów w danych.
- Ścieżka Audytu: Pełny, chronologiczny zapis operacji systemu, niezbędny do celów regulacyjnych.
Ważne: Interfejs uzyska pełną funkcjonalność po zintegrowaniu z API Trinity.
Decyzja nie wynika z pojedynczej odpowiedzi modelu, lecz z rozkładu odpowiedzi w przestrzeni znaczeń. Trinity nie pyta „czy model ma rację”, ale mierzy, jak bardzo modele są ze sobą zgodne, gdzie się rozjeżdżają i w którym miejscu pojawia się niestabilność logiczna.
Architektura operuje na trzech warstwach walidacyjnych:
– warstwie syntaktycznej (spójność struktury odpowiedzi),
– warstwie semantycznej (zgodność sensu w przestrzeni embeddingów),
– warstwie inferencyjnej (ciągłość i niesprzeczność wnioskowania).
Dopiero agregacja tych warstw w czasie rzeczywistym pozwala zidentyfikować:
– odpowiedzi pozornie poprawne, lecz logicznie kruche,
– odpowiedzi spójne, ale semantycznie dryfujące,
– odpowiedzi stabilne i powtarzalne w wielu instancjach modelu.
Trinity nie zwiększa „inteligencji” modelu.
Zwiększa kontrolę nad niepewnością.
System redukuje halucynacje nie przez filtrowanie treści, lecz przez wykrywanie ich strukturalnej niestabilności. Zamiast blokować wynik — mierzy jego rygor. Zamiast ufać pojedynczej instancji — analizuje konsensus równoległy.
W efekcie LLM przestaje być czarną skrzynką generującą tekst, a staje się komponentem probabilistycznym podlegającym pomiarowi.
To przejście od generowania odpowiedzi
do zarządzania wiarygodnością.
Trinity nie jest kolejnym modelem ani dodatkiem funkcjonalnym do LLM.
To warstwa metrologii decyzyjnej, która wprowadza mierzalny rygor do systemów generatywnych.
Zamiast ufać pojedynczej odpowiedzi, Trinity analizuje rozkład zgodności, stabilność semantyczną i ciągłość logiczną w środowisku równoległych instancji modeli. Wynik nie jest opinią modelu — jest wskaźnikiem jego spójności.
W świecie, w którym AI generuje coraz więcej treści, kluczowe staje się nie to, co zostało wygenerowane, lecz jaka jest jakość strukturalna tej odpowiedzi.
Trinity przesuwa punkt ciężkości:
– z produkcji tekstu na kontrolę miar
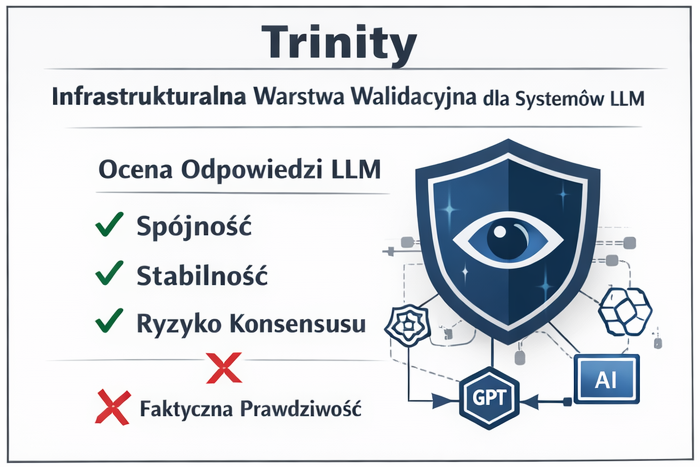
Trinity — Infrastrukturalna Warstwa Walidacyjna dla Systemów LLM
Trinity to warstwa infrastrukturalna zapewniająca mierzalną walidację odpowiedzi generowanych przez duże modele językowe (LLM) przed ich wykorzystaniem w procesach decyzyjnych. System nie generuje odpowiedzi, lecz ocenia ich spójność, stabilność i ryzyko metodami kwantytatywnymi, dostarczając audytowalnego sygnału decyzyjnego dla środowisk wysokiego ryzyka.,
– ze statystyki na decyzję.
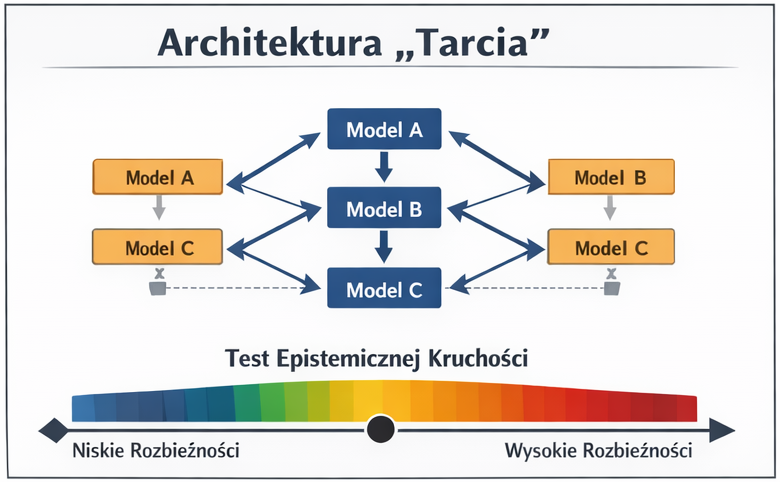
Architektura tarcia
Trinity wymusza konfrontację między wieloma modelami (GPT, Claude, Gemini, Minstral, Grok…), analizując odpowiedzi przez hierarchiczny system metryk:
Poziom 1: Metryki surowe
- TF (Tarcie Logiczne) — mierzy rozbieżność semantyczną między odpowiedziami różnych modeli metodą podobieństwa cosinusowego embeddingów
- K_Sem (Dryf Semantyczny) — kwantyfikuje stabilność pojedynczej odpowiedzi względem perturbacji parametrów generacyjnych
Poziom 2: Meta-stabilność
- nΔK_Sem (Znormalizowana Zmiana Dryfu Semantycznego) — wykrywa anomalie systemowe przez wynik z-score zmian K_Sem między przebiegami (progi heurystyczne 2σ/3σ wymagające empirycznej kalibracji przy niespełnionej normalności rozkładu)
Poziom 3: Metryki syntetyczne
- SC_Index (Indeks Syntetycznego Konsensusu) — kondensuje TF i K_Sem w jednowymiarowy sygnał ryzyka fałszywego konsensusu
- ART (Analiza Rygoryzmu Terminalnego) — agreguje cztery wymiary jakości: logikę, konsistencję, niezależność i minimalność (wymaga formalizacji definicji operacyjnej)
Poziom 4: Klasyfikacja kontekstowa
- TRL (Tolerancja Ryzyka Logicznego) — adaptacyjnie klasyfikuje kontekst ryzyka (STABILNE/RYZYKOWNE/KRYTYCZNE) i wyznacza wymagane progi pewności (hybryda heurystyczno-empiryczna kalibrowana na danych pilotażowych)
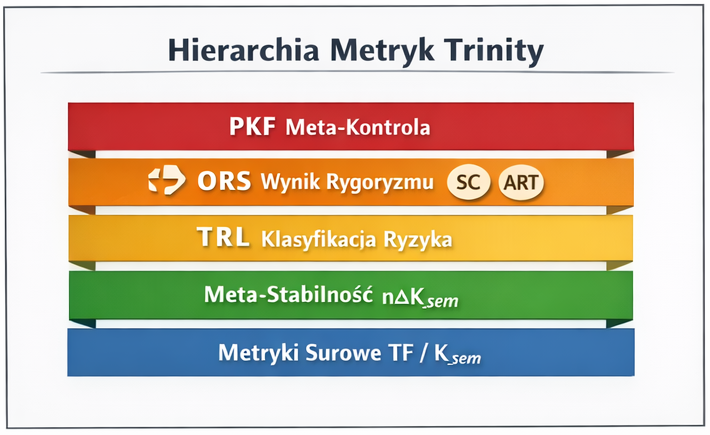
Poziom 5: Kondensacja decyzyjna
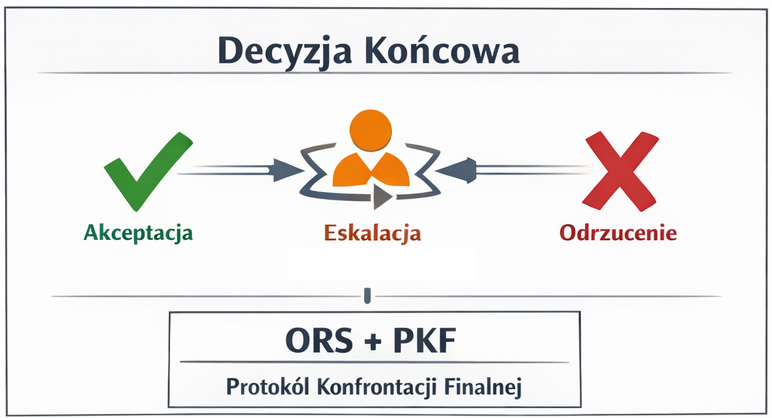
PKF (Protokół Konfrontacji Finalnej) — meta-kontrola z prawem veta działająca jako nieliniowa warstwa nadrzędna nad ORS, stanowiąca ostateczną warstwę bezpieczeństwa
ORS (Wynik Rygoryzmu Wyjściowego) — metryka domyślna łącząca wszystkie wymiary walidacyjne z zasadą dziedziczenia rygoru (najsłabszy wymiar ogranicza wynik końcowy), generująca decyzję operacyjną: akceptacja / eskalacja (człowiek w pętli) / odrzucenie
Przepływ decyzyjny — objaśnienie warstw
Stochastyczna odpowiedź LLM
Każda odpowiedź generowana przez LLM ma charakter probabilistyczny i zależy od parametrów generacji (temperatura, seed, top-p, itp.). Ten etap stanowi punkt wejścia do systemu i źródło pierwotnej niepewności epistemicznej.
Orkiestracja wielu modeli (≥3 modele × zapytanie)
System równolegle uruchamia wiele modeli, wymuszając konfrontację niezależnych przestrzeni generatywnych. Celem jest ujawnienie rozbieżności ukrytych przy pojedynczym przebiegu oraz redukcja ryzyka artefaktów jednego modelu.

Metryki surowe (TF, K_Sem) — rozbieżność i stabilność
Na tym etapie mierzone są podstawowe własności odpowiedzi:
- stopień rozbieżności semantycznej pomiędzy modelami,
- stabilność znaczeniowa odpowiedzi przy perturbacjach generacyjnych.
Jest to bezpośredni pomiar spójności epistemicznej, bez agregacji i interpretacji kontekstowej.
Meta-stabilność (nΔK_Sem) — wykrywanie anomalii
Analizowana jest dynamika zmian stabilności pomiędzy kolejnymi przebiegami. Celem jest wykrycie zachowań anomalnych, niestabilnych lub wskazujących na systemowy dryf odpowiedzi, który nie jest widoczny w pojedynczym pomiarze.
Kondensacja syntetyczna (SC_Index, ART)
Wielowymiarowe sygnały walidacyjne są agregowane do postaci syntetycznej. Na tym poziomie system przechodzi od pomiarów do oceny jakości strukturalnej odpowiedzi, uwzględniając jej rygor, spójność oraz odporność na pozorny konsensus.
Klasyfikacja kontekstu (TRL) — wyznaczenie progów
System identyfikuje kontekst ryzyka decyzji i dostosowuje wymagane progi akceptacji. Ten etap umożliwia różnicowanie rygoru walidacji w zależności od domeny, krytyczności i potencjalnych konsekwencji błędu.
ORS — decyzja domyślna [0,1]
Na podstawie wszystkich wcześniejszych sygnałów wyznaczany jest ciągły wynik decyzyjny. ORS reprezentuje domyślną ocenę systemu, przy czym obowiązuje zasada dziedziczenia rygoru — najsłabszy wymiar ogranicza wynik końcowy.
PKF — meta-kontrola (prawo nadpisania)
Końcowa warstwa bezpieczeństwa posiadająca prawo veta wobec decyzji ORS. PKF działa jako nieliniowa meta-kontrola, umożliwiająca eskalację lub blokadę decyzji w przypadkach granicznych lub systemowo podejrzanych.
Decyzja finalna + pełna ścieżka audytu
System generuje finalną decyzję operacyjną (akceptacja, eskalacja, odrzucenie) wraz z kompletną, audytowalną ścieżką: od odpowiedzi źródłowych, przez wszystkie metryki i klasyfikacje, po reguły nadpisania.
Krytyczne ograniczenia i założenia metodologiczne
Trinity weryfikuje spójność epistemiczną, nie prawdziwość faktograficzną. System wykrywa niestabilność, niejednoznaczność i podejrzany konsensus, ale nie weryfikuje poprawności merytorycznej odpowiedzi. Obecna architektura nie zawiera komponentów:
- Weryfikacji krzyżowej ze źródłami zewnętrznymi
- Zakotwiczenia faktograficznego (weryfikacja w faktach)
- Estymacji niepewności (entropia tokenowa, prawdopodobieństwo logarytmiczne)
Założenia statystyczne wymagające weryfikacji empirycznej:

- Progi nΔK_Sem (2σ/3σ) mają charakter heurystyczny przy często niespełnionej normalności rozkładu ΔK_Sem (skośność, grube ogony, wielomodalność)
- W środowiskach produkcyjnych zalecane jest przejście na percentyle empiryczne lub statystyki odporne przy naruszeniu założenia normalności
Komponenty w fazie formalizacji:
- ART — brak pełnej definicji operacyjnej metody obliczania (stanowi najsłabszy element formalny w systemie aspirującym do pełnej audytowalności)
- TRL — przejście od deterministycznego silnika reguł do hybrydy heurystyczno-empirycznej wymaga logowania wersji algorytmu przy każdej decyzji dla zachowania audytowalności
Redundancja strukturalna:
- SC_Index jest funkcją TF i K_Sem, dlatego ich równoczesne użycie w ORS tworzy współliniowość (nie jest to błąd matematyczny, ale zwiększa wagę TF i K_Sem w decyzji finalnej)
Zakres stosowania
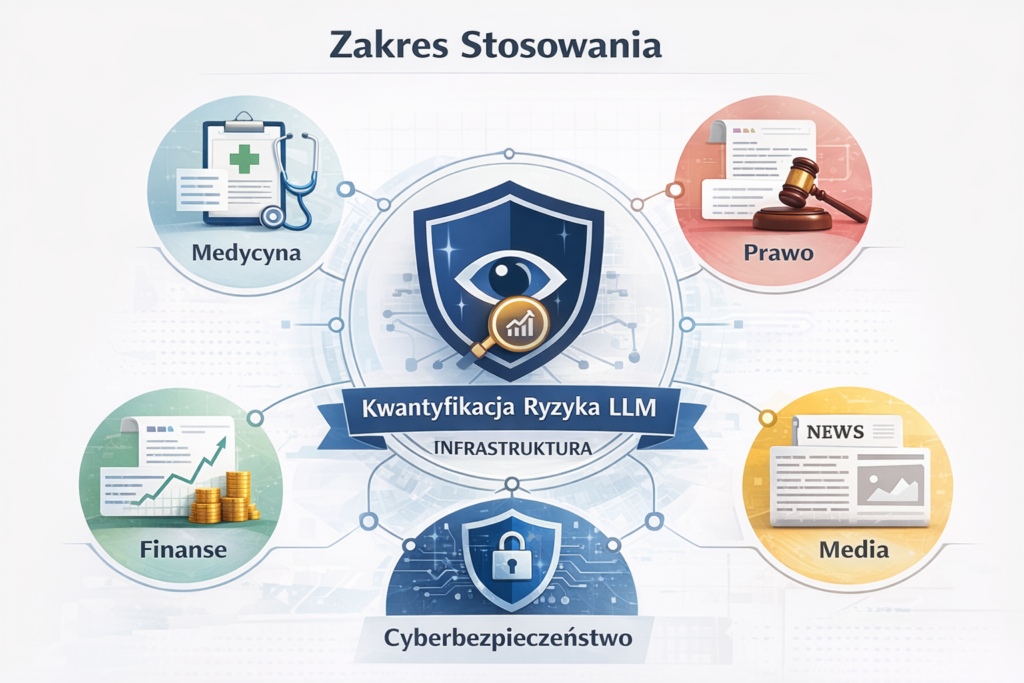
System jest projektowany dla środowisk wysokiego ryzyka wymagających audytowalnego procesu decyzyjnego opartego na LLM: medycyna, prawo, finanse, cyberbezpieczeństwo, media. Trinity nie zastępuje weryfikacji faktograficznej ani nadzoru ludzkiego, lecz stanowi warstwę infrastrukturalną umożliwiającą kwantyfikację ryzyka przed podjęciem decyzji.
Status projektu: Zaawansowany prototyp badawczy klasy roboczej z działającym rdzeniem obliczeniowym metryk i orkiestracją wielu modeli. Pełna kalibracja produkcyjna wymaga empirycznej walidacji na danych z pilotaży klienckich w środowiskach docelowych.
Charakterystyka techniczna:
- Dualny tryb operacyjny (kontrolowany dla testów deterministycznych / rzeczywisty dla produkcji)
- Metryki oparte na embeddingach semantycznych
- Pełna ścieżka audytu każdej decyzji
- Adaptacyjna kalibracja progów na danych rzeczywistych wdrożeń
- Hierarchiczna architektura decyzyjna z meta-kontrolą PKF jako ostatecznym arbitrem
Zrób pierwszy krok w kierunku sukcesu już dziś.
ZAINWESTUJ TERAZ
„Za rok to będzie standard — a Ty będziesz jego współwłaścicielem.”